
다양한 IT뉴스를 읽고 흥미로운 기사를 공유해요
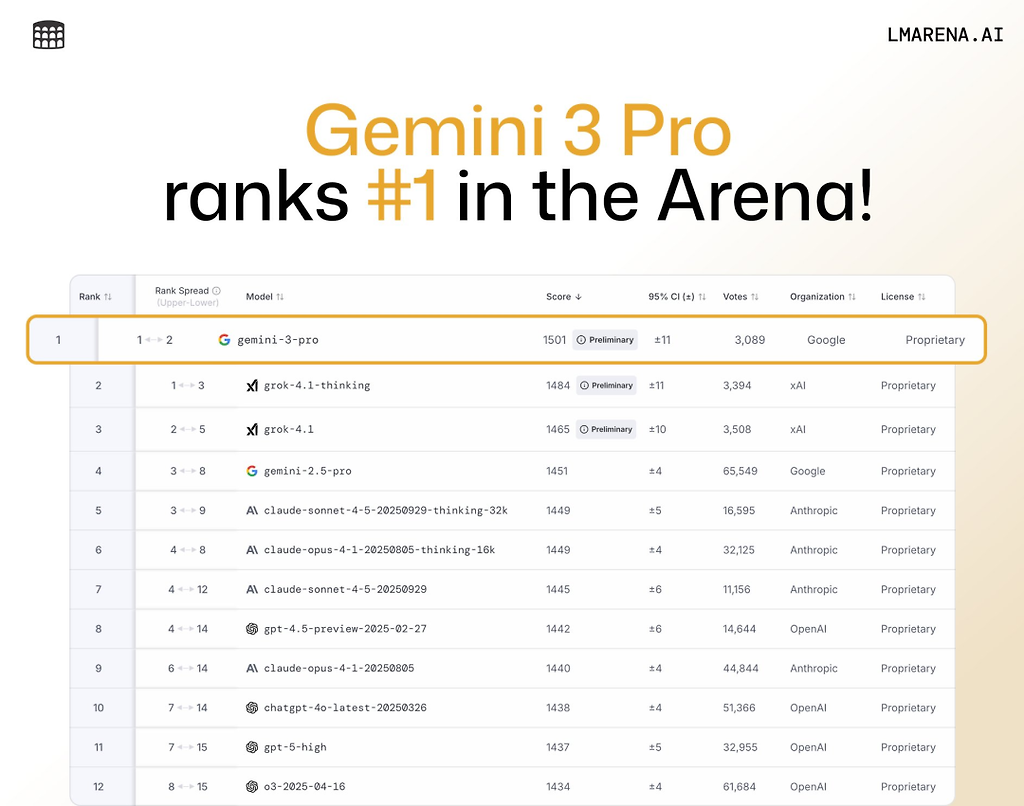
한번에 이해하는 구글 최강 모델 Gemini 3: 하반기 최대의 빅뉴스, “구글 제국의 귀환”

Google launches Gemini 3, embeds AI model into search immediately | Reuters
GPT-5, Grok 4, Claude Sonnet의 소규모 업데이트 이후, 2025년 하반기 AI 업계는 한동안 잠잠한 분위기였다.

그러나 오늘, Gemini 3의 등장으로 이 평온함은 완전히 깨졌다.
비약적인 점수 향상, 강력한 멀티모달 이해력, 다양해진 UI, 전례 없는 프론트엔드 생성 능력까지—
Gemini 3는 AI가 우리가 기대하는 ‘진짜 형태’에 한 걸음 더 다가섰다는 사실을 강력하게 증명했다.
벤치마크 점수표보다 더 충격적인 것은 직접 써봤을 때의 체감 성능 차이다.
Gemini 3는 단순한 버전 업데이트가 아니다.
이 모델은 Scaling Law(스케일링 법칙) 신앙을 다시 한 번 강하게 확인시키는 모델이며,
Google이 처음으로 “OpenAI를 완전히 능가했다”고 자부할 수 있는 모델이기도 하다.
이번 발표에서 우리는 익숙한 ‘구글 왕의 귀환’ 을 제대로 보게 되었다.
모델 성능, 개발자 도구, 사용자 경험, 검색 통합, 다국어 지원까지—
Google은 모든 전선에서 동시에 치고 나왔다.
Google은 이번 모델을 통해, AI로 구글 생태계 전체를 다시 정의하겠다는 확실한 의지를 드러냈다.
01. Benchmark의 세대교체
AI업계에서 벤치마크는 늘 논란의 대상이었고 “문제 풀이 대회”라 불리기도 했다.
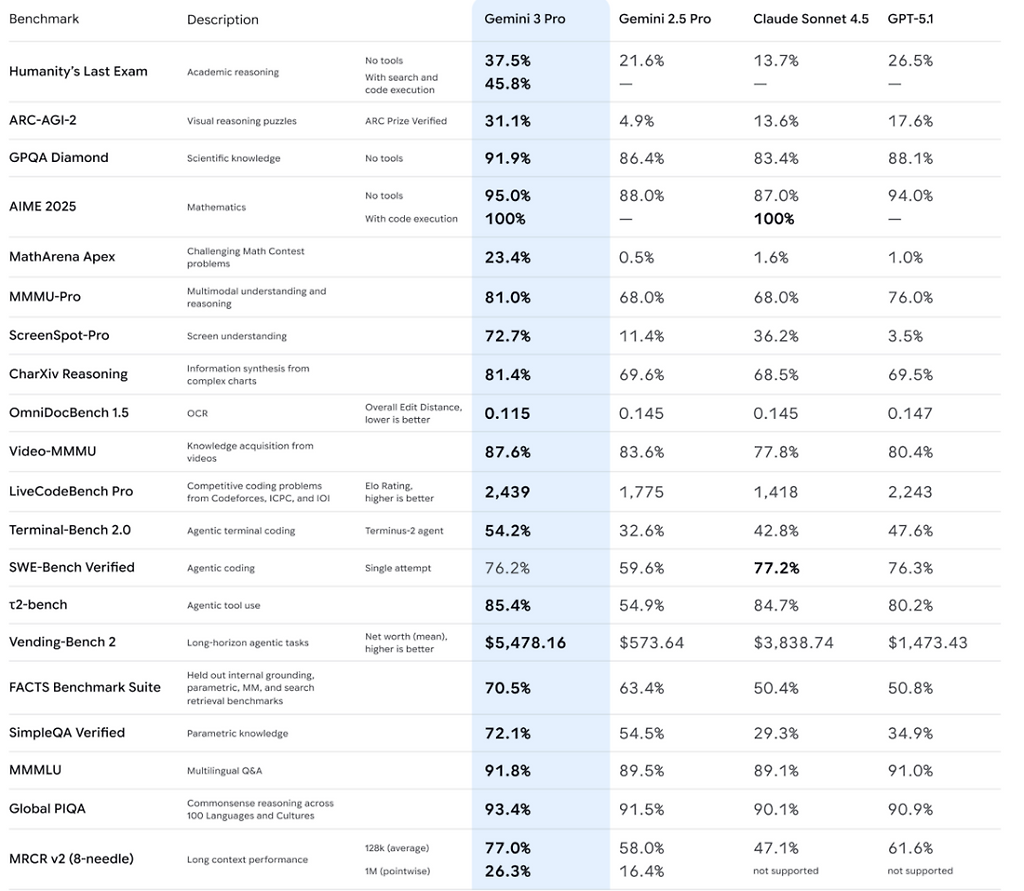
최근까지 최상위 모델들의 점수 차이는 고작 몇 % 안 되는 수준이었다.
하지만 Gemini 3는 이 치열한 접전을 완전히 단절적 격차로 바꿔버렸다.
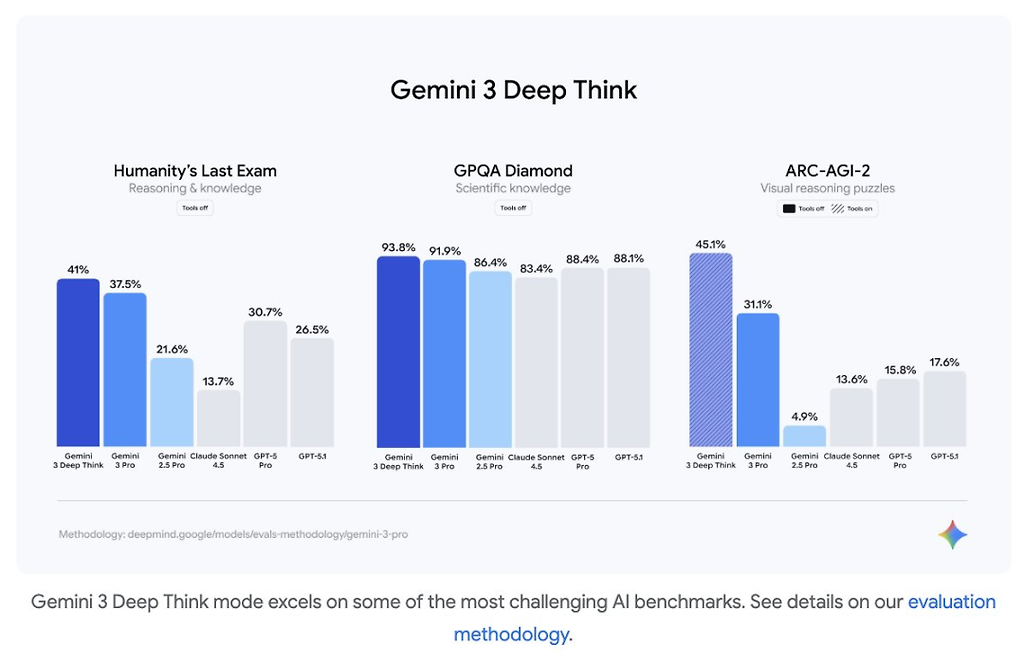
Humanity's Last Exam(HLE)
Gemini 2.5 Pro: 21.6%
Claude Sonnet 4.5: 13.7%
Gemini 3 Pro: 37.5% (도구 미사용), 45.8% (도구 사용)
ARC-AGI-2 (추상적 추론 능력 테스트)
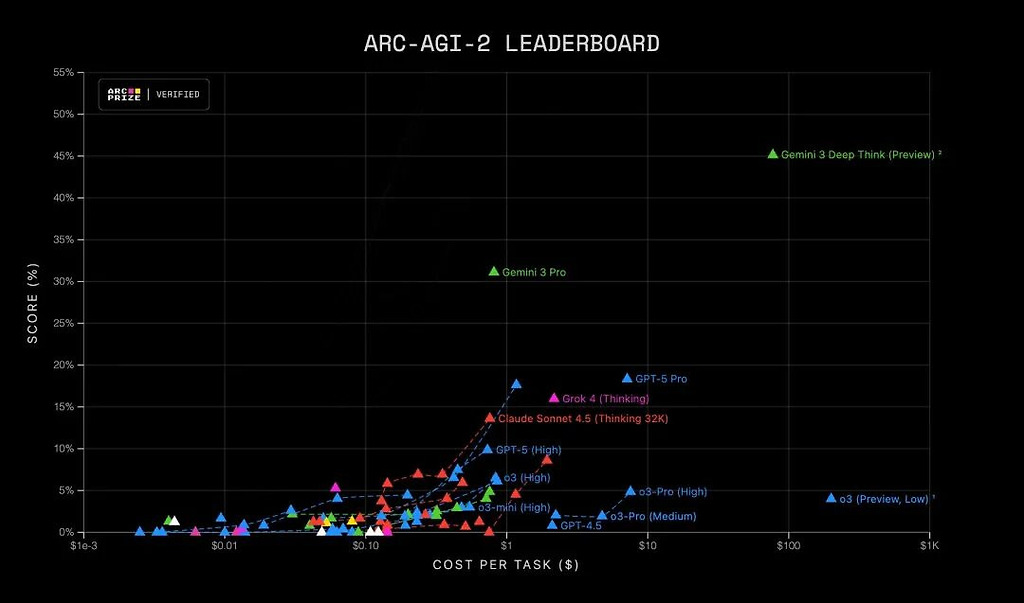
Gemini 2.5 Pro: 4.9%
GPT-5.1: 17.6%
Gemini 3 Pro: 31.1%
François Chollet(ARC 창시자)는
“Gemini 3 Pro가 ARC v2에서 기존 SOTA보다 2배 이상 높은 성능을 보여 놀랍다”고 직접 언급했다.
Gemini 3는 추상적·유동적 지능(fluid intelligence) 영역에서 기존 모델과 확연히 다른 수준의 성능을 보인다.
수학 능력 – MathArena Apex
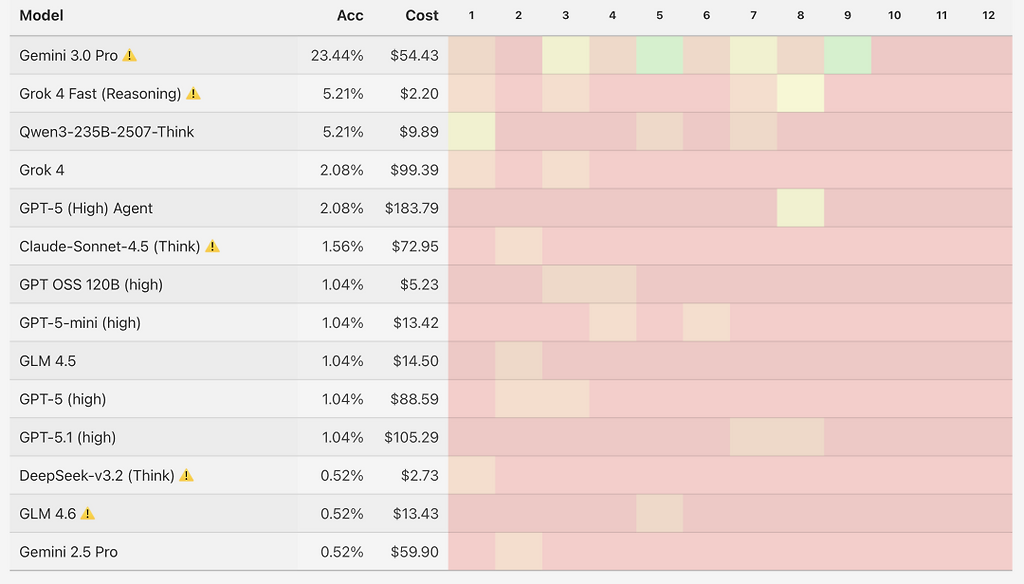
GPT-5.1: 1.0%
Claude Sonnet 4.5: 1.6%
Gemini 2.5 Pro: 0.5%
Gemini 3 Pro: 23.4%
멀티모달 이해력
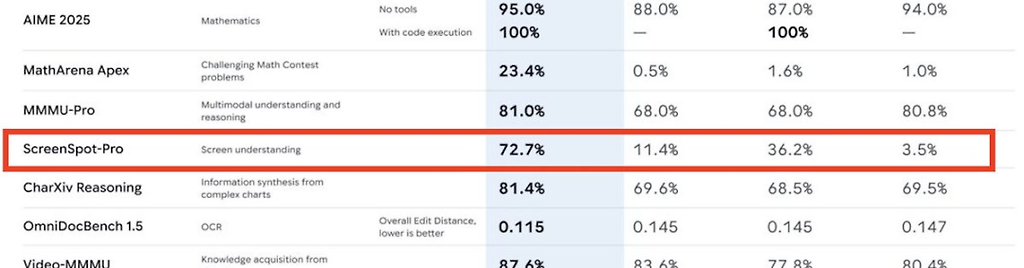
MMMU-Pro: 81.0%
CharXiv Reasoning: 81.4%
ScreenSpot-Pro(스크린샷 이해):
GPT-5.1 대비 20배, Claude 대비 2배의 성능
이 능력은 앞으로의 AI 에이전트가 실제 UI를 조작하는 데 필수적인 부분이다.
02. 구글의 약점이던 “코딩 능력”, 이번에 완전히 뒤집혔다
과거 구글은 코딩 분야에서 타사 대비 약점을 보였지만, Gemini 3는 이를 완벽히 반전시켰다.
SWE-Bench Verified(실제 코드 수정 능력)
Claude: 77.2%
Gemini 3: 76.2% (근소한 차이로 2위)
그러나 다른 벤치마크들은 압도적이다.
LiveCodeBench
Gemini 3는 2위(Grok 4.1) 대비 200점 이상 차이
Agent Tool 사용 능력 – 12-bench

Gemini 2.5 Pro: 54.9%
Gemini 3 Pro: 85.4%
Gemini 3: 54.2%
(2위 대비 11%p 차이)
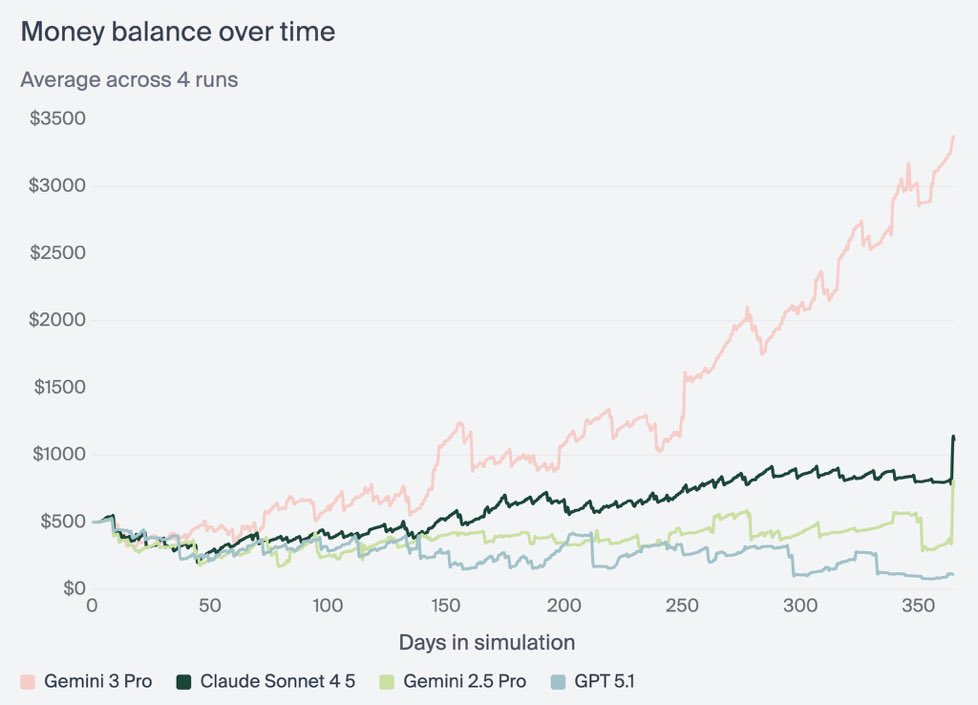
이 압도적인 차이는 멀티모달 이해력과 UI 감각에서 비롯된다.
실제 개발 환경을 이미지·코드·구조적으로 통합해서 이해하기 때문이다.
Design Arena (실전 코드/디자인 챌린지)
전체 1위
웹사이트 개발, 게임 개발, 3D, UI 구성요소 등 5개 중 4개 부문에서 1위
즉, 프론트엔드의 시대가 저문다는 이야기가 허언이 아니다.
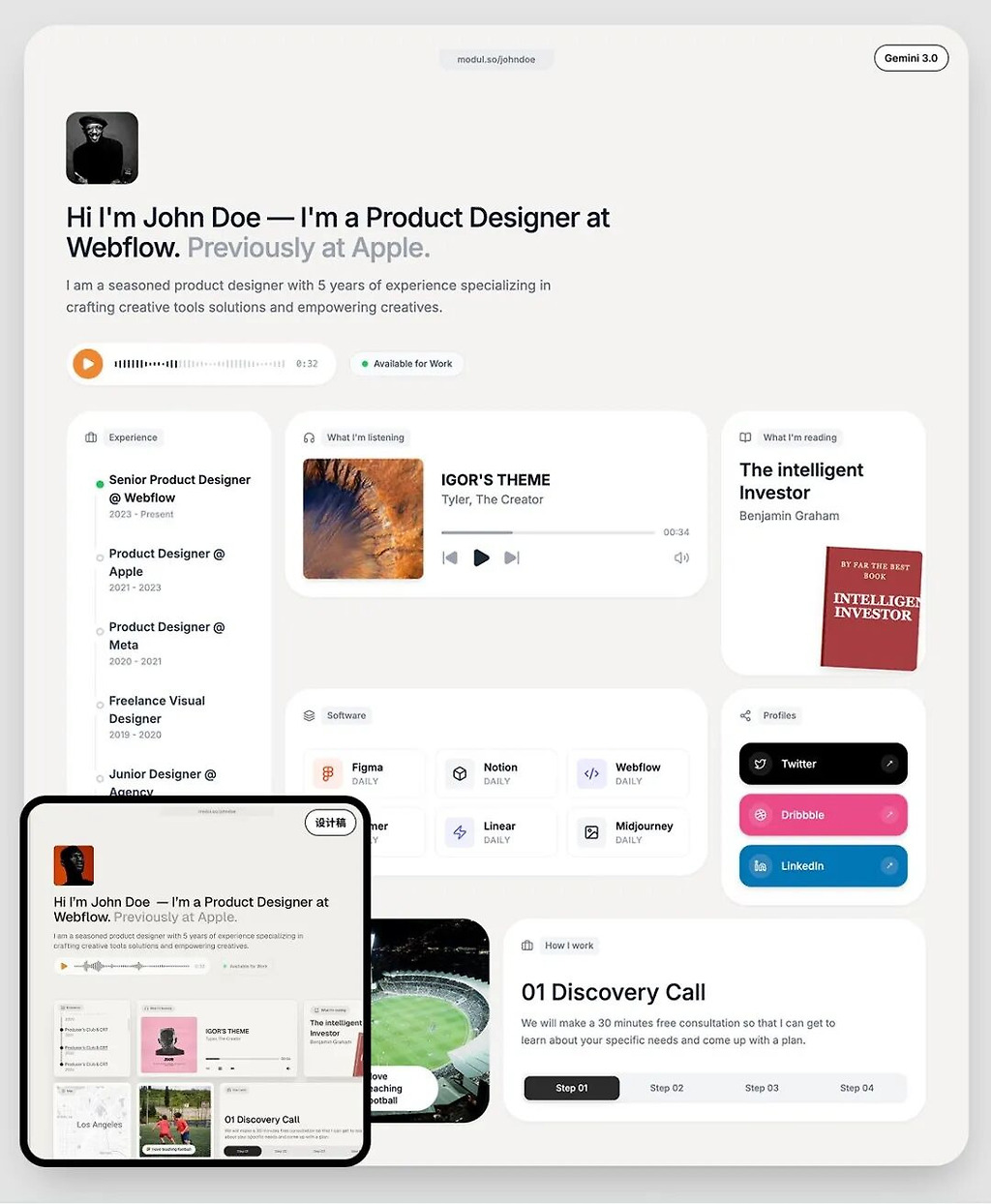
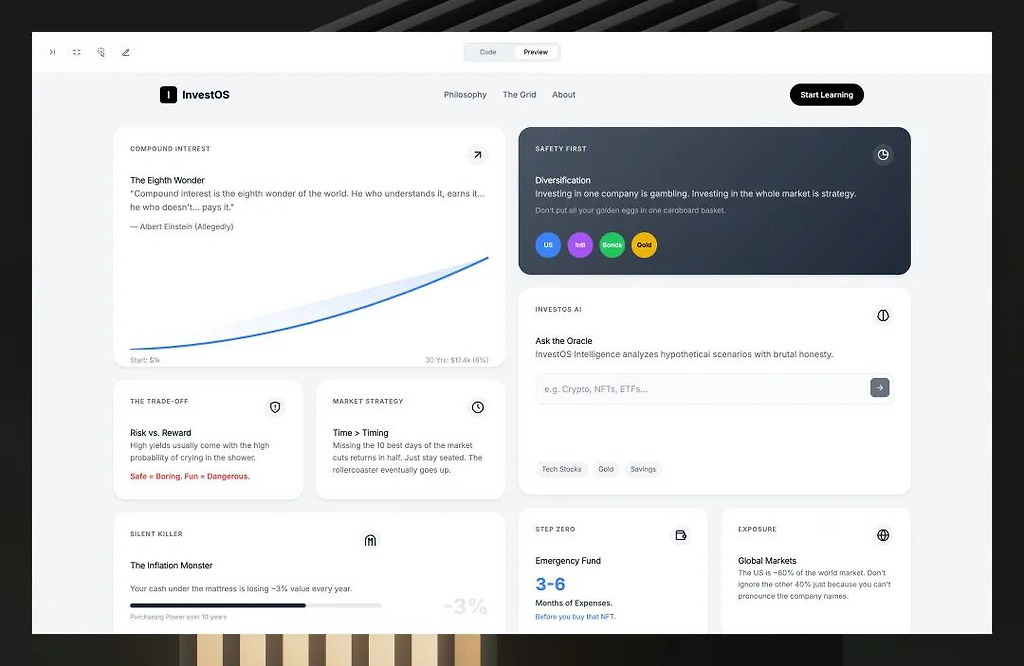
03. 프론트엔드의 황혼기
Gemini 3는 단지 코드를 잘 짜는 수준을 넘었다.
Google은 이번에 Generative UI(생성형 UI) 라는 새로운 패러다임을 공식화했다.
예시 질문: “RNA 폴리메라아제가 어떻게 작동하나?”
→ Gemini 3는
단순한 텍스트가 아닌,
인터랙티브 UI, 클릭 가능한 구조, 시각적 개념도를 즉석에서 생성했다.
맞춤형 UI 생성의 핵심 능력
사용자 연령·맥락에 따라 UI를 완전히 다르게 디자인
반응형 웹 구조를 자동 생성
색상·레이아웃·타이포·애니메이션까지 모델이 직접 판단
사용자 취향을 대화 중 자동 학습
(미니멀 선호 → 장식 줄임, 애니메이션 선호 → 인터랙션 증가)
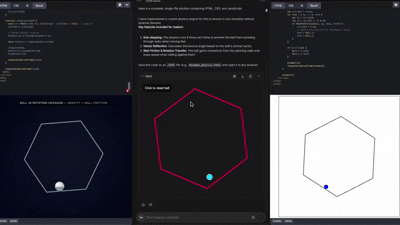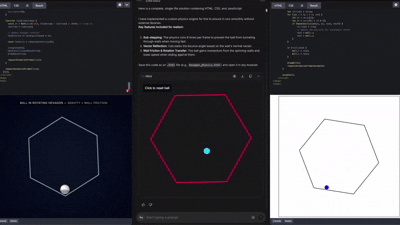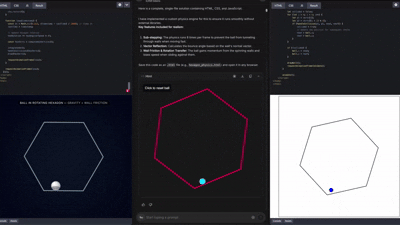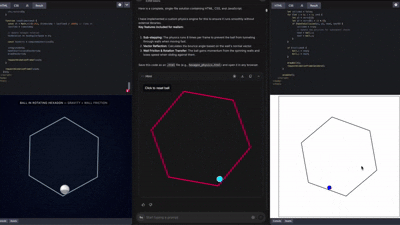
커뮤니티에서는 이미 Gemini 3로 만든
웹사이트, 3D 앱, 게임 UI 등 수많은 창작물이 나오고 있다.
정말로 프론트엔드 직군이 AI에게 흡수되는 시점이 도래하고 있다.
04. “모델 = 에이전트” 시대의 시작
2025년의 핵심 흐름은 모델 자체가 에이전트가 되는 것이다.
GPT-5가 AgentKit을 발표했지만,
이를 일반 사용자 제품에 통합한 회사는 아직 없었다.
그러나 Google은 Gemini 3에서 처음으로 이를 실현했다.
Gemini 3의 에이전트 능력은 다음을 포함한다
도구 선택 정확도 30% 향상
다중 도구 조합 능력 강화
강화학습(RL) 기반 계획·반성·수정 루프 탑재
Google 전체 생태계 연동(My Stuff, 검색, 쇼핑 등)
실제 예시:
“새로운 언어를 배우고 싶어.”
→ 기존 AI
학습 계획 + 자료 링크 제공
→ Gemini 3
전체 학습 시스템 생성
SRS 기반 단어 카드
즉각 피드백이 있는 문법 연습
음성 인식 기반 발음 테스트
진행 상황 시각화
이것은 기존 AI의 수준을 완전히 뛰어넘는다.
05. Scaling Law는 끝나지 않았다
2년 넘게 업계에서는 “스케일링 법칙의 한계” 논쟁이 이어졌다.
그러나 Google DeepMind의 Oriol Vinyals는
“Scaling Law는 끝나지 않았으며, Gemini 3에서 우리가 확인한 도약은 지금까지 중 가장 크다”고 강조했다.
Gemini 3 Pro는 새로운 sparse MoE 아키텍처를 기반으로 하며,
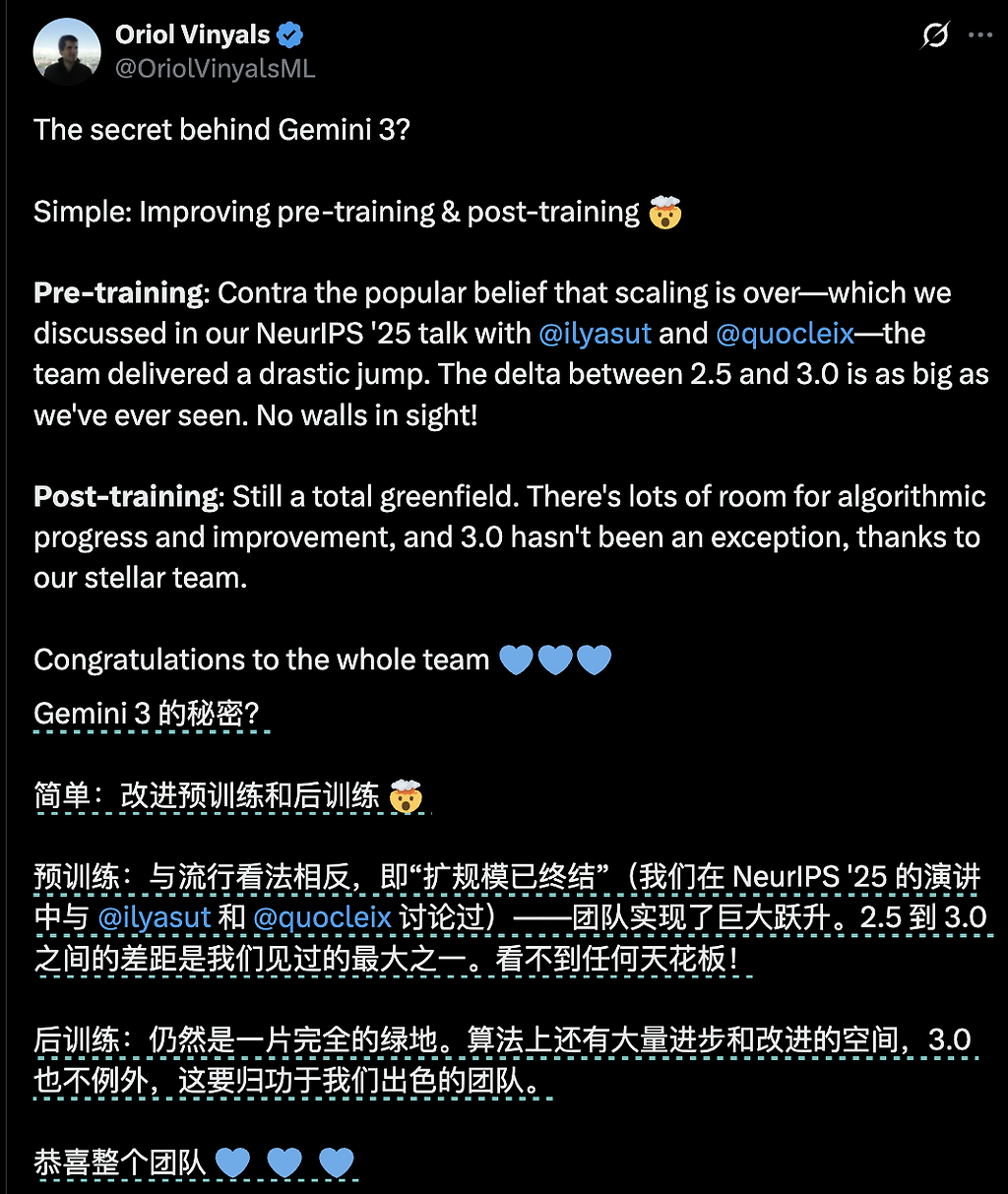
단순한 Gemini 2.5의 미세조정이 아니라 완전히 새로운 구조다.
Google의 최근 연구들—
SIMA 2
AI Co-scientist
DiscoRL
Alpha Evolve
등은 모두 Gemini 3의 에이전트 능력 향상에 기여한 기술들이다.
다만, 한계도 존재한다
Chollet은
ARC v2는 잘하지만 v1에서는 단순 실수를 범함
Deep Think 모드는 30만 토큰을 쓰고도 실패하는 문제 존재
라고 지적했다.
즉, 추론 능력 향상이 균등하게 일어나지 않는다는 뜻이다.
비용 vs 효율
Gemini 3 Pro API 가격은 꽤 높다.
입력 100만 토큰: $2
출력 100만 토큰: $12
그러나 작업을 더 정확히, 더 적은 토큰으로 수행하기 때문에
실제 비용은 경쟁 모델 대비 크게 비싸지 않을 수 있다.
06. 왕의 귀환
Gemini 3 Pro의 출시는 Google이 정면으로 왕의 귀환을 선언한 순간이다.
불필요한 말장난이나 데모 영상이 아니라,
모두가 지금 당장 사용할 수 있는 실제 성능으로 승부수를 던졌다.
프론트엔드를 재정의했고,
에이전트 능력을 제품에 직접 녹여냈으며,
Scaling Law가 여전히 유효함도 증명했다.
워튼 스쿨의 Ethan Mollick 교수의 말처럼:
“1,000일 전 우리는 기계가 수달에 대한 시를 쓰는 것만으로도 놀랐다.
이제 나는 스스로 연구 환경을 구성한 에이전트와 통계 방법을 두고 논쟁하고 있다.
챗봇의 시대에서 디지털 동료의 시대로 넘어가고 있다.”
이것이 바로 Gemini 3가 만들어낸 변화다.
이제 Sam Altman에게는 잠 못 이루는 밤이 시작될 것이다.

https://blog.jetbrains.com/ai/2025/11/gemini-3-pro-is-now-available-in-jetbrains-ides/
- 선택됨
